IoTで使うPython入門Step1-I2C LM75Bで温度測定 (2) Pythonの型
ラズパイとI2CインターフェースのLM75Bをつないで温度を読み出すプログラムをPythonで記述しています。いつもとりあえず動くプログラムしか書いていないのですが、中身を検討します。ここでは、型、シフト、n進数変換を取り上げます。
●データの型
前回のLM75Bをsmbusライブラリで温度を読み出して表示するプログラムです。
C言語のように型の宣言がどこにもないので、調べてみます。
import smbus
import time
i2c = smbus.SMBus(1)
addr = 0x4c # LM75B NXP. TI is 9bit
def sign16(x):
return (-(x & 0b1000000000000000) | (x & 0b0111111111111111))
# main
while 1:
data = i2c.read_i2c_block_data(addr, 0,2)
raw = ((data[0]) << 8) | (data[1])
print(hex(data[0])),
print(hex(data[1])),
print(hex(raw))
raw_s = sign16(int(hex(raw), 16))
temp = (raw_s >> 5) * 0.125
print(str(temp) + "C")
time.sleep(1)
知りたいのはdata、raw、data[0]、tempです。print(type(xx))で調べました。
| 変数名 | 型 class |
|---|---|
| data | list |
| raw | int |
| data[0] | int |
| temp | float |
dataは配列だと思ったのですが、リストでした。調べるとPythonにはarray(配列)はあるのですが、モジュールとしてimportしないと使えないので、メジャーではないようです。arrayとlistはどちらもデータを連続して収納していて、それぞれの要素にインデックスが振られています。arrayはその要素が全部同じ型でないといけないけれど、listはそうでなくともよいというのです。listのほうが自由度が高いけど、配列として扱っても違和感がないですね。
listの収納されるデータの型が異なるとすれば、箱が並んでいるのではなく、順序づけられた集合体としてみるのがよいのかもしれません。インターネットを検索しても配列としか扱っていない説明が目につきます。筆者も配列とばかり思いこんでいたので、慣れてから、本質的なlistの使い方を学んでいきたいと思います。
listは初期化が不要で使えます。というより、ほかの変数も宣言せずに使っていますが。明示的に初期化もできます。
| data[]=0 |
各要素へはインデックス値でアクセスします。最初はdata[0]で、次はdata[1]です。最初からデータを入れることもできます。
| data=[65,41] |
とすれば、data[0]は65で、data[1]は41です。data[0]の内容を書き換えるには、
| data[0]=88 print data # [88,41] |
です。#はコメント行を表すのによく使われています。追加は、
| data.append(20) print data # [88,41,20] |
後ろに追加されています。
元に戻って、波形を見ます。この波形は、読み出し時にdata = i2c.read_i2c_block_data(addr, 0, 2)と記述しました。最後のパラメータは読み出すバイト数です。実は前回忘れていました。忘れると、確認はしていないのですが32バイト読み出されているようです。最初の2バイト以降はゴミです。読み出しの動作自体は正常に行われます。
このデバイスはポインタ(0は温度が入っているポインタ・レジスタ)を指定しているので、ごみデータも読み出しています。そのデータが存在しないと思われる領域を読み出すために不都合が起こり、動作が止まることがあるかもしれません。これがレジスタであれば、連続するほかのレジスタもまとめて読めるので便利なこともあります。1バイト目が上位バイトで、3バイト目が下位バイトとかいう変な収納をしているデバイスのときなど役立ちます。とはいえ、32バイトも読み出すとノイズをまき散らすことになるので、必要最小限のバイト数にしましょう。
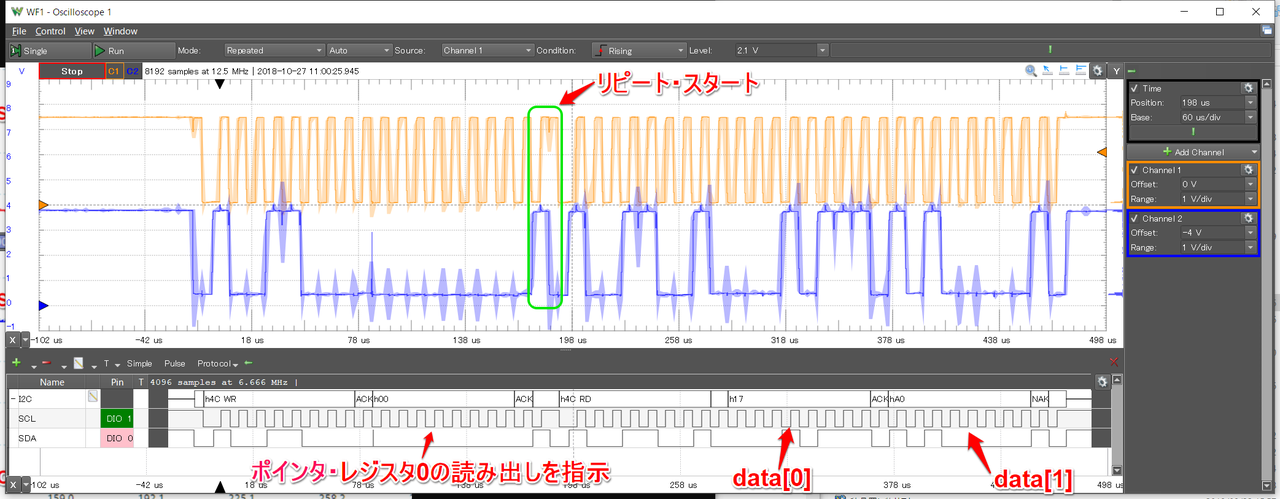
下側のI2Cデコード画面で、8ビット単位で見ます。最初にマスタがスレーブ・アドレス0x4c(7ビット)を送り出します。LSBはWriteです。ストップ・コンディションにはならず、リピート・スタート・コンディション(※1)に移行します。
最初にLM75Bが送ってくるデータがdata[0]に入り、次の1バイトがdata[1]に読み込まれます。最後はNAK(NAck)でマスタがスレーブに終わりだと告げ、ストップ・コンディションで通信終了です。
LM75Bのマニュアルに書かれているデータ・フォーマットです。
| 上位バイト | 下位バイト | ||||||||||||||
| bit7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | bit7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D11 | D10 | D9 | D8 | D7 | D6 | D5 | D4 | D3 | D2 | D1 | D0 | x | x | x | x |
I2CはMSBからデータを送るので、たぶん上位バイトのMSBから送っているはずです。受け取ったdata[0]と[1]の内容が明らかに逆だったら、入れ替えます(次回取り上げる)。温度データは確認しやすいです。マニュアルに、データと温度の対応が掲載されています。室温だと25℃付近の値なので見当がつきます。
| バイナリ 11ビット | 16進 | 10進 | 温度[℃] |
|---|---|---|---|
| 000 1100 1000 | 0x0c8 | 200 | +25.000 |
| 000 0000 0001 | 0x001 | 1 | +0.125 |
| 000 0000 0000 | 0 | 0 | 0 |
| 111 1111 1111 | 0x7ff | -1 | -0.125 |
読み出した直後は16ビットです。上記の表示は11ビットなので、25℃は8ビット単位で見れば、上位「0001 1001」、下位「000x xxxx」です。
| print(bin(data[0])), print(bin(data[1])), |
で表示すると、下位バイトはパラパラと変化します。上位バイトは、急に変化はしないという規則性があると推測してデータを見ます。指でつまむと上位バイトの数値が増えるはずです。
10進数を2進、16進に変換する方法です。結果は文字列になります。
| 2進 バイナリ BIN | bin(4) | 'b0100' |
| 16進 ヘキサ HEX | hex(128) | '0x80' |
●符号ビットの処理
多くの温度センサやA-Dコンバータの2の補数形式では、最上位ビットに符号が来ます(※2)。 読み出した上位データのMSBが1であればマイナスの温度、0ではプラスの温度です。データが全部0であれば0℃です。
def sign16(x):
return (-(x & 0b1000000000000000) | (x & 0b0111111111111111))
関数はdefで書き初めて関数名の最後は:です。処理本体はインデントを付けます。戻り値はなし、1個だけ、複数が記述できます。上記は戻り値が一つです。全体をかっこで囲っていますが、必要かどうかはわかりません。
このsign16()は、符号を判断して、負の数ならマイナスをつけて戻ってきます。プラスの温度データならば、そのまま何もせずに値を戻します。細かく見ていきます。まず、左側のブロックです。
| x & 0b1000000000000000 |
左側のブロックで使っているビット演算子&は、論理積(AND)です。xと0b1000000000000000の両方で1だと1で、どちらかもしくは両方が0だと0です。なので、符号が1であれば結果は1です。ほかは0です。
次は右のブロックです。
| x & 0b0111111111111111 |
右側のブロックでは、最上位ビット以外を全部1でAND演算しているので、最上位ビットは0になり、それ以下のビットは、元のデータxと同じになります。
両方のブロックの演算をビット演算子|(論理和 OR)で演算するので、左辺と右辺の同じ位置にあるビットのどちらかが1であれば1(両方1であれば1を含む)に、両方とも0のときは0です。
結果、符号ビットが1であれば、-符号が追加された以外は元のデータが、符号ビットが0であれば、元のデータがそのまま戻ります。
このLM75Bのプログラムでは、読み出した直後16ビットのデータで、左詰めの形式なので、16ビットのデータで符号判断をしています。もし、11ビットに変換した後ならば、次のように11ビット長さにすれば、同様に符号処理ができます。
| return (-(x & 0b10000000000) | (x & 0b01111111111)) |
実際に符号処理を呼び出しているところです。何やら複雑な記述ですね。たぶん、データが正しく取れなかったときに試行錯誤していたなごりです。10進のrawを16進に変換して、16進のデータを10進に変換しています。
raw_s = sign16(int(hex(raw), 16))
したがって、なにもせず、raw_s = sign16(raw)でよいわけです。
10進への変換です。変換後はintになります。
| 16進 | int('80', 16) | 128 |
| 2進 | int('101', 2) | 5 |
int(0x80,16)は、
| TypeError: int() can't convert non-string with explicit base |
とエラーが出ます。0x80は文字列ではないので変換できないといっています。
| hex(0x80) # '0x80' |
文字列になっているようです。print(type(hex(0x80)))の結果は、str=文字列でした。
●シフト
1バイトずつ読み込んだデータを16ビットにするのにシフトを使います。
raw = ((data[0]) << 8) | (data[1])
左に1回シフトすると倍に、右に1回シフトすると半分になります。
| a = 0x80 print a<<1 |
は256です。
| print a>>1 |
は64です。
最初に読み込んだdata[0]はtypeで調べるとintでした。intは16ビットと仮定し、0x80が入っているとすると、
| - | - | - | - | - | - | - | - | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
8回左にシフトすれば、
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
になります。これは0x8000ですから、10進では32768です。128*256=32768です。aの128を2^8倍したのと同じです。ごめんなさい。2^8はGoogleで計算するときの記法ですね。調べるとPythonは2**8もしくはpow(2, 8)を使うようです。
2番目のデータdata[1]を0xffとします。
| - | - | - | - | - | - | - | - | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
8回左にシフトしたdata[0]と論理和ORを取ります。どちらかが1であれば1になります。
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
結果です。読み込んだ上位バイトと下位バイトがintにそのまま収まりました。
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
24ビットのデータだと3バイトが必要です。シフトさせるのは同じ要領でできますが、intが16ビットなら桁があふれるように思えます。
| 「5ドル!ラズパイ・ゼロ(Raspberry pi Zero)でIoT (47) アナログ温度センサ5 白金抵抗体、ADS1220」 data = (adc[1] << 16) | (adc[2] << 8) | adc[3] |
うまく動いているようです。調べるとラズパイのintは32ビットもしくは64ビットでした。十分大きいです。
temp = (raw_s >> 5) * 0.125
16ビットのデータのうち温度データは左詰めで11ビット分が入っているので、右に5回シフトすれば、右詰めになります。シフトした結果、上位の5ビットは0が入るようです。
0.125を掛けているのは、データシートに最小分解能は0.125℃と書かれているからです。数学的な根拠は? 勉強中です。もし上位バイトの8ビットだけを扱うとき、最小分解能は1℃です。LM75Bの確度(accuracy)が±2℃なので、8ビットで読み出すのでもよいような気がします。プログラムも簡単になりますし。
(※1)リピート・スタート・コンディションは、smbus2の時代にi2c_rdwrとして実装されたようです。現在、smbusとsmbus2は統合されているように見えます。
じつは、今ここで使っているバージョンpython-smbus 3.xのドキュメントが見つからないのです。
(※2)最上位バイトをオーバフローなどの目的で使っているデバイスもあります。